
GM Software Deliverable
There are three parts to this deliverable: - Source code implementing GPU kernel-scheduling middleware - Source code implementing a CUDA micro-benchmark program - Document giving an introduction to the two implementations along with instructions for installation and running an example of using the middleware
Kernel-Scheduling Middleware
Introduction This library implements a transparent extension to the NVIDIA runtime API (libcudart) that is dynamically linked with CUDA programs. This extension provides a "middleware" scheduling infrastructure that controls CUDA kernel launch requests. It was designed to control kernel scheduling for CUDA programs having the following characteristics commonly used for concurrent GPU sharing. Using the middleware with a CUDA program having these characteristics does not require any changes to the CUDA source code.
- A main process that creates multiple threads (pthreads) sharing a single process address space (i.e., the conditions under which kernels can run concurrently on a GPU).
- Each thread creates one user-defined CUDA stream (FIFO queue) that it manages and uses for invoking GPU operations. There is a one-to-one relationship between threads and streams.
- The program is written to launch kernels using the angle-brackets syntax (<<<.....>>>) and synchronizes the CPU and GPU with at least one call to cudaStreamSynchronize() between successive instances of kernel launches in a given stream.
- The CUDA program is dynamically linked with the CUDA library libcudart
In the case of a CUDA program with multiple user-defined streams, the NVIDIA scheduling rules for choosing among multiple streams with kernels at the top of their FIFO queues are not documented. This middleware attempts to implement and control some of the scheduling choices that can be made.
The library functions are transparently invoked by "wrapping" calls to certain of the original CUDA API functions and performing scheduling choices before or after invoking the "real" CUDA code. Control over which kernel launch requests can be issued to the NVIDIA software and hardware scheduling mechanisms is achieved by blocking and signaling operations on the program threads.
The new library functions were designed following the fundamental principle of separation
between mechanism and policy. Most of the library implements the mechanisms that are
required for any policy. Many scheduling policies are possible given adequate mechanisms for
carrying out a given policy. The separation of mechanism and policy makes it easy to try out
and evaluate different policies. In the library code, all aspects of policy are implemented in a
single function, find_next_kernel(), which returns either an identifier for a stream to launch a
kernel or -1 to indicate that no new launch is allowed. The policy functions are intended to be
implemented as instances of the find_next_kernel() function each contained in a .h file named
in a #include statement.
A complete description of the software, including specific details, can be found in the extensive comments embedded in the source code.
CUDA Micro-Benchmark Program
Introduction
The CUDA program gpuBench.cu is a multi-thread, multi-kernel micro-benchmark program
to emulate running multiple instances form a specified set of kernel descriptons. The kernels
launched are randomly selected from the set using the specified parameters for each kernel.
The kernel parameters are:
- frequency each kernel from the set is launched
- execution attribute (compute-intensive or memory-intensive)
- number of blocks in the kernel
- number of threads in the block
- kernel execution times (expressed as loop counts in kernels)
- delays between kernel launches
Kernel execution attributes are implemented by two micro-kernels: - a compute-intensive kernel that uses 32-bit floating-point operations with data held in registers only. - a memory-intensive kernel that uses both 32-bit integer operations and memory references.
This program implements multiple POSIX threads and each thread manages one user-defined stream with asynchronous kernel launches. cudaStreamSynchronize() is used to wait for any operations in the stream to complete. Host pinned memory is used.
A complete description of the software, including specific details, can be found in the extensive comments embedded in the source code.
Instructions for Installing and Executing the Programs
Installation
The software has been tested on an NVIDIA Jetson TX2 with CUDA version V9.0.252 but should
work with any CUDA Version 9 installation.
- Place the tar file in a directory you will be using for running the software and extract the
contents. This should produce a top-level directory containing:
- a directory named gpuScheduler which contains the source code for the
scheduling middleware
- a directory named gpuBenchmark which contains the source code for the
micro-benchmark program
- change directory to gpuScheduler and enter
make. This should produce a dynamic link library namedlibcudart_wrapper.so. - change directory to gpuBenchmark and enter
make. This should produce an executable CUDA program namedgpuBench
Example of using the middleware scheduler
This example illustrates running the middleware for scheduling kernels executed by the micro-
benchmark program, gpuBench, produced from the make described above. It launches
compute-intensive kernels as defined in the include file compute_config.h in the
gpuBenchmark directory. The middleware dynamic-link library generated from the make step
above uses the scheduling policy implemented in the file MinFitMinIntfR2.h. The policy is
"min thread use, min interference", i.e., find the ready-to-launch kernel that will occupy the
smallest number of available GPU threads AND does not fail a test for interference effects. The
test for interference effects requires that ratio between the number of threads in the kernel
under consideration and any kernel already scheduled does not exceed a threshold (in this
implementation, 2.0). This test is motivated by empirical measurements that have shown
interference effects as much as 500% or higher for large thread ratios between concurrently
executing kernels. Figure 1 (below) shows these effects when the compute-intensive
benchmark is run without the scheduling middleware using only the default NVIDIA software
and hardware. Note that the kernels with smaller numbers of threads (128 to 640) have longer
than expected execution times and they are highly variable with worst-case to best-case ratios
of 7:1 or more. These data were obtained by using NVIDIA’s nvprof tool to generate a GPU
trace of all process activity.
To run the benchmark with the scheduling middleware, change directory to gpuBenchmark and run the following two commands at the command line (these commands can also be found in the README file in that directory, and help for the program parameters can be obtained by invoking gpuBench with the –h switch).
cp ../gpuScheduler/libcudart_wrapper.so .
LD_PRELOAD=./libcudart_wrapper.so ./gpuBench -k 200 -t 4 -rs 0
This runs the gpuBench program (dynamically linked with the scheduling middleware) with 4 threads each executing 200 kernels and using a fixed random number seed for each thread. The program executes for about 7 to 8 minutes on a TX2 running at the maximum CPU, GPU, and memory clock speeds.
Figure 2 (below) shows the effects of the scheduling policy on compute-intensive kernels. Comparing Figure 2 with Figure 1, we see that kernel execution times are reduced for all kernels but with dramatic reductions in execution time and execution variability for kernels having a number of threads between 128 and 640. This scheduling policy does require a trade-off between reduced execution times for kernels and potential blocking of launches to enforce minimal interference. Whether reduced execution times offset increased blocking times or not will depend on the particular mix of kernels and should be evaluated for each application.
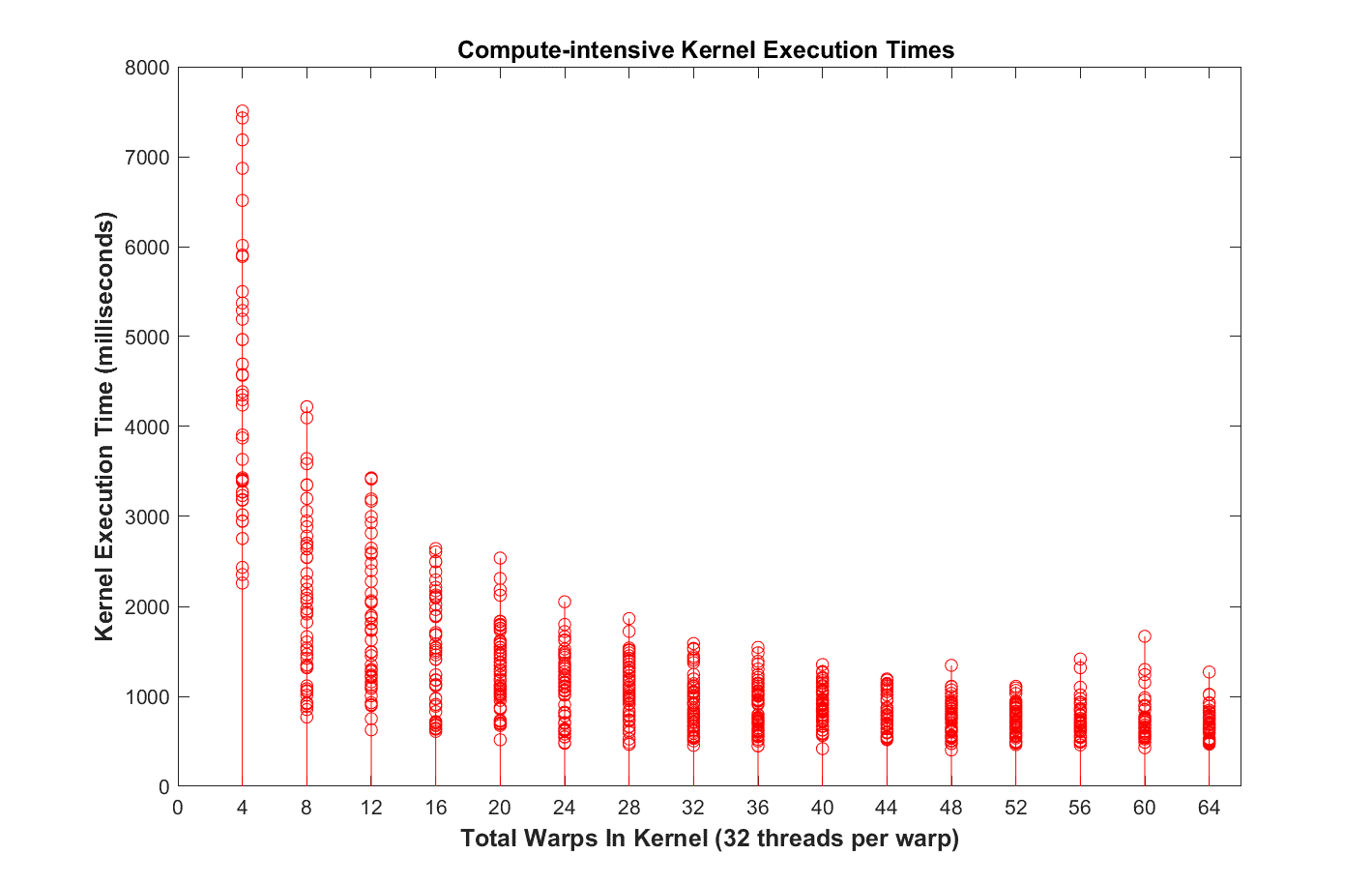
Figure 1. Compute-intensive kernel execution times for different numbers of threads when scheduled by the default NVIDIA scheduling software and hardware.
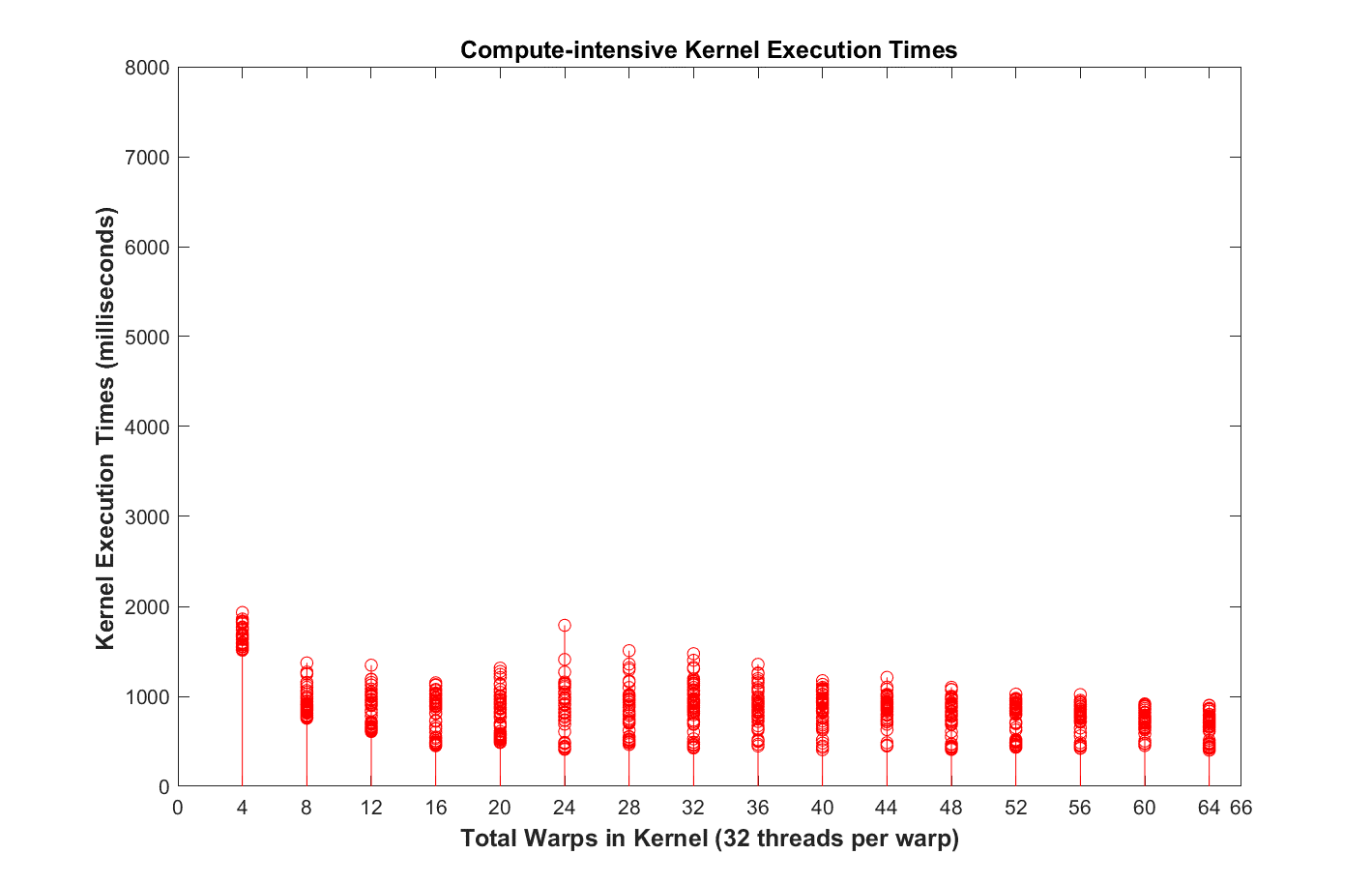
Figure 2. Compute-intensive kernel execution times for different numbers of threads when scheduled by middleware extensions to the CUDA runtime using a policy of minimizing inter- kernel interference.